
Having AST capabilities built into the tooling that we use in our day-to-day tasks as developers provides a lot of value when we’re trying to deliver reliable and secure products, even though it can feel like an excessive requirement that’s just there to meet corporate standards. There are IDE plugins for performing local checks before you commit to Git, and it seems like there are countless scanners throughout the CI/CD pipeline, from pull requests to production. Each one has a reason to be there, and each one is significant for maintaining a secure application profile.
These scans do provide valuable data. For example, they can find places that reference old libraries, which could lead to defects and after-hours calls from panicked operations folks. In addition to reducing avoidable defects, scans can identify variables and unused dependencies that cause application bloat. They can even make sure that the code is styled in the same way (so you can finally pick a winning side in the tabs vs. spaces flame war).
So Many Places, So Little Time
The larger and older your organization is, the more likely it is that you’re using scanning technology that’s been mixed and matched. There are a few reasons for this. For one, the organization’s suite of tools was likely assembled over time, which probably involved finding solutions to new requirements in a vacuum. The chosen tool might have been best-of-breed or the absolute cheapest available, depending on who was running the procurement cycle at the time. In addition, the organization might lack a centralized approach, either because they just allowed different development groups to do their own thing, or because they experienced many different mergers and left acquisitions semi-autonomous.
In an environment where there are multiple tools from multiple vendors, each with its own method of retrieving data, it can be a daunting task for a developer just to remember all of the scans that he or she needs to perform, not to mention keep track of where to get the results of each one. In situations like this, aggregation can be a huge help.
There are several different levels of aggregation, and achieving any one of them is a step in the right direction. For example, you can aggregate the process of kicking off all of your scans using hooks in your favorite version control software at a certain gateway step (like a merge request). This approach allows developers to find all of the results for any scans that the organization requires. You can even have them block requests until any issues are resolved.
For example, you might see something like this if you’ve integrated scans into GitHub pull requests:
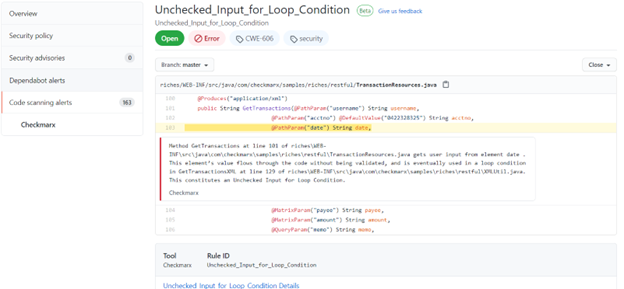
(source: https://github.com)
Another example of aggregation is a dashboard that combines all of the results into a single, easy-to-access view. This approach doesn’t seem to be as common, since some of the tools involved may not have an API or an easy point of integration. Some organizations, however, have the luxury of standardizing their security testing with a single vendor that provides end-to-end integrations and a convenient console. This usually comes about when the organization finally gets serious about its investment in security.
One View to Rule Them All
Single-vendor consoles come closest to what a developer might consider the peak of ease-of-use, which would be the correlation of all results from all scans against any application code base in context.
Bits and pieces of this ideal do exist – like the ability to show a list of dependencies that are out of date, or the ability to show static code results in an IDE by highlighting lines that are not up to the required standards. But it isn’t all shown in context, and it’s missing other things – like the results of IAST scans that can pinpoint a dependency or line of code that’s causing an error.
Once these bits and pieces have been brought together in a single console, vendors could take it even further by integrating runtime data generated by CWPP, CASM, CWPS, or CNAPP tooling (which watches the live environment and constantly looks for ways to improve and areas that need attention.) Vendors could also extend beyond security data to include APM suites that developers use to gather usage data that allows them to fine-tune and enhance their applications.
Conclusion
Aggregating the results of all the various security scans that an application undergoes from keyboard to production in a single place is a great first step. It would be even better if you had a few entry points to get to the results. But having a centralized view where you could see all of the relevant issues while viewing the code would be best. Vendors are getting there, and developers are just waiting for them to take that next step so that all of that consolidated data can be brought into their safe place: the code. Instead of merely achieving an operations-friendly environment, this last step would create a utopia for developers.
If you’re looking to leverage a single vendor for all of your AppSec needs, consider the Checkmarx One™ Application Security Platform. Checkmarx One is built from our industry-leading AppSec solutions—SAST, SCA, IaC, API Security, Container Security, and Supply Chain Security (SCS)—and delivered from the cloud. It provides rapid, correlated, and accurate results to speed remediation all on a single, unified report.
Bio

Vince Power is an Enterprise Architect with a focus on digital transformation built with cloud enabled technologies. HE has extensive experience working with Agile development organizations delivering their applications and services using DevOps principles including security controls, identity management, and test automation. You can find @vincepower on Twitter.