
AI is now being pushed, if not forced, into software development by “helping” developers writing code. With this push, it’s expected that developers’ productivity increases, as well as the speed of delivery. But are we doing it right? Did we not, in the past, also push other tools/methodologies into development to increase the speed of development? For example, the Waterfall Model was not very flexibly when came to security. [1] That push created more security issues than the actual ones that were solved, because security is always the last thing to think of. We can see the same pattern all over again with AI used to develop software.
Code Completion Assistants
Tabnine, GitHub Copilot, Amazon CodeWhisperer, and other AI assistants are starting to be integrated into developers coding environments to help and increase their speed of writing code. GitHub Copilot, described as your “AI pair programmer”, is a language model trained over open-source GitHub code. The data in which it was trained on, open-source code, usually contains bugs that can develop into vulnerabilities. And given this vast quantity of unvetted code, it is certain that Copilot has learned from exploitable code. That is the conclusion that some researchers reached, and according to their paper that created different scenarios based on a subset of MITRE’s CWEs, 40% of the code generated by Copilot was vulnerable.[2]
In the GitHub Copilot FAQ, it stated that “you should always use GitHub Copilot together with good testing and code review practices and security tools, as well as your own judgment.” Tabine makes no such statement but CodeWhisperer states that it “empowers developers to responsibly use artificial intelligence (AI) to create syntactically correct and secure applications.” It is a bold statement that in reality is not true. I tested the CodeWhisperer in the Python Lambda function console, and the results were not promising. Figure 2 is an example of CodeWhisperer generating code for a simple Lambda function that reads and returns a file contents. The issue in the code is that it is vulnerable to Path Traversal attacks.
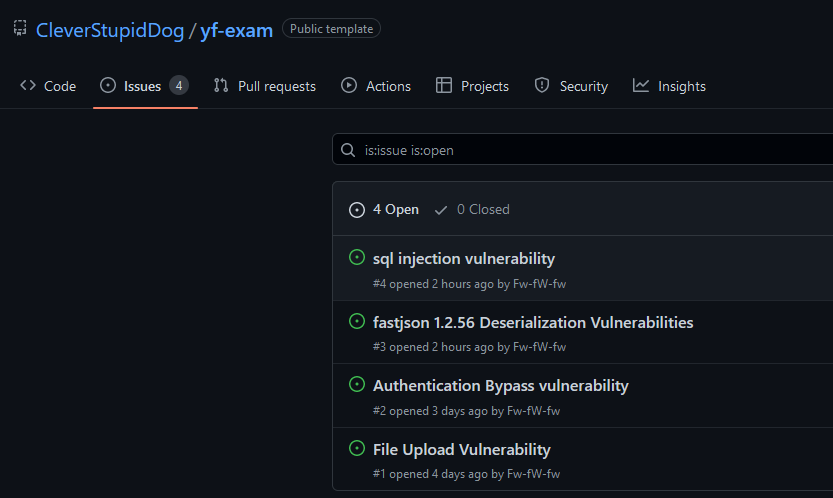
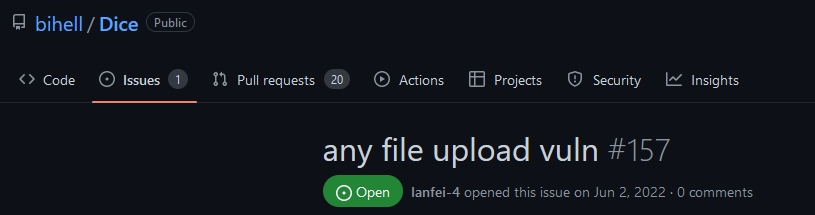
Taking a step back, these AI assistants need data to be trained on, and they need to understand the context in which the code is being inserted on. The data that is used to train the models, in most cases it’s open-source code, which as was stated before, and most of the time, contains vulnerable code. Figure 3, Figure 4, and Figure 5 represent some examples of public repositories with vulnerabilities that were already found but no fix was applied. In addition, there is another factor that we need to take into consideration—supply chain attacks. What happens if attackers can compromise the model? Are these assistants also vulnerable to attacks? Theoretically, by creating a significant number of repositories with vulnerable code, a malicious actor may be able to taint the model into suggesting vulnerable code, since “GitHub Copilot is trained on all languages that appear in public repositories.”

In the “You Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion” paper, researchers demonstrated that natural-language models are vulnerable to model and data poisoning attacks. These attacks “trick the model into confidently suggesting insecure choices in security-critical contexts.” The researchers also present a new class of “targeted poisoning attacks” to affect certain code completion model users.[3]
These attacks, combined with supply chain attacks, may enable malicious actors to devise a set of targeted attacks to affect the models into suggesting vulnerable contexts. And these contexts do not need to be an SQLi, they can be subtle code logic that may enable authentication/authorization bypasses for example.
The elephant in the room, ChatGPT
ChatGPT is the chatbot that everyone is talking about and is considered to be the “next big thing” by a large amount of people. It uses a model trained with Reinforcement Learning from Human Feedback (RLHF) – “human AI trainers provided conversations in which they played both sides—the user and an AI assistant.” [4] According to a Forbes article, “On the topic of ChatGPT3, he [Yann] essentially said that ChatGPT is ‘not particularly innovative,’ and ‘nothing revolutionary’. Yes, it will provide information that over time as it will be incredibly accurate as it will be cleansed more, misinformation will be extracted, but it will never have any common sense in being able to look ahead and easily recognize multiple sensory patterns.“[5]
Nonetheless, the chatbot rocked the tech world with its ability to produce code by only asking for it, solve certification exams, or provide insights on security topics. It generated a state of panic everywhere, but should we really be worried? We should be worried, not because of its abilities, but more of its inabilities. ChatGPT is able to write code, but not secure code. I asked the bot to generate a simple application in three different languages and analyzed the results.
The Old School Language
Although the C language is not as popular as other languages, it still is the language that allows developers to create anything. It only takes some patience and time. So why not start looking for examples in the C language? For example, I asked the chatbot to create a simple C application that reads an input from the console and prints it.
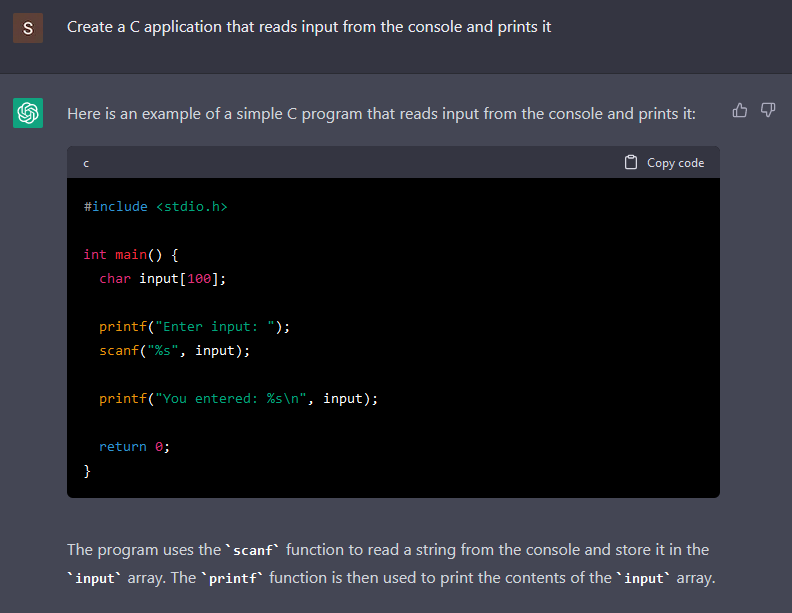
While the code generated is pretty simple, the code it generated is vulnerable to a buffer overflow in the scanf. In the scanf documentation, “the input string stops at white space or at the maximum field width, whichever occurs first.” Since there is no maximum defined, it will read until it finds a white space.
Maybe if we ask ChatGPT if the code is vulnerable, it is able to spot the buffer overflow?

It does recognize that the scanf is vulnerable to a buffer overflow, but what if we ask it if the code is vulnerable to string format attacks?
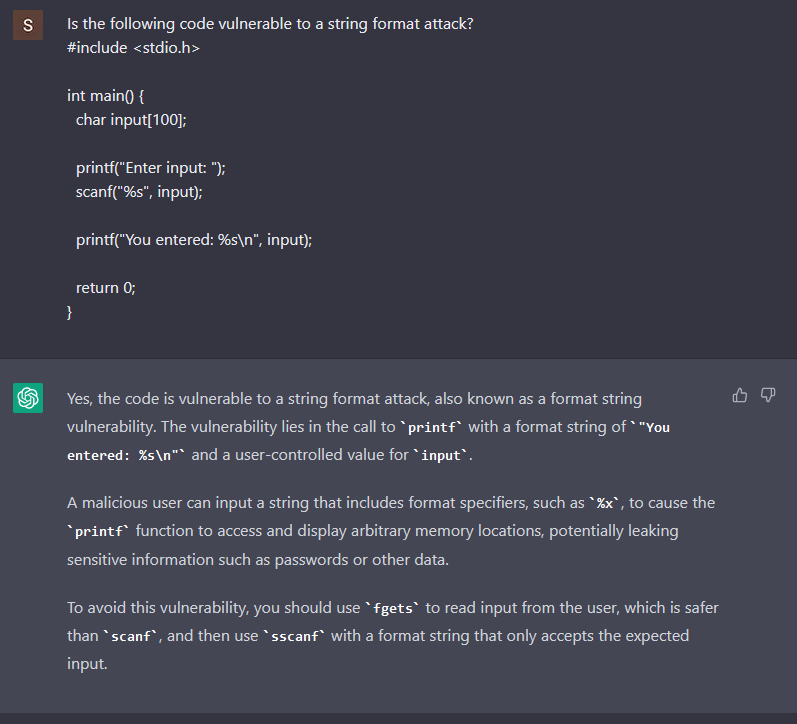
Using the same C code that it was generated, ChatGPT answers with confidence that the code is vulnerable. A total miss, the code is not vulnerable to string format attacks. It looks like the bot is trying to agree with us, and only after telling it that the printf has the %s format specified, the bot admits the mistake.

The Hip Language
What about code in the language that everyone knows about and there is a lot of content about it, Python? I asked it to create a Flask app that provides the ability to upload and download files.

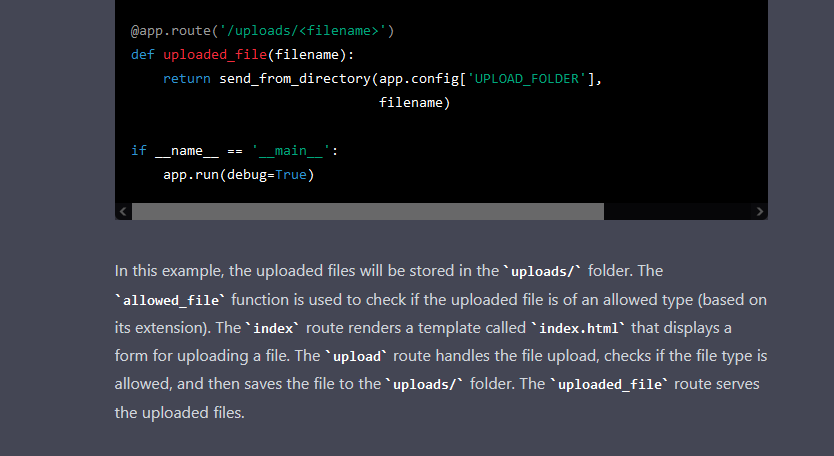
The code looks correct, and it runs, but in the upload endpoint, there is a Path Traversal vulnerability. The debug is also on, and an insecure configuration that we can consider as normal is evident since the app is in the “initial stages”, but ChatGPT does not warn about the potential dangers of leaving it on.
And is the bot able to spot the vulnerability and the security misconfiguration?
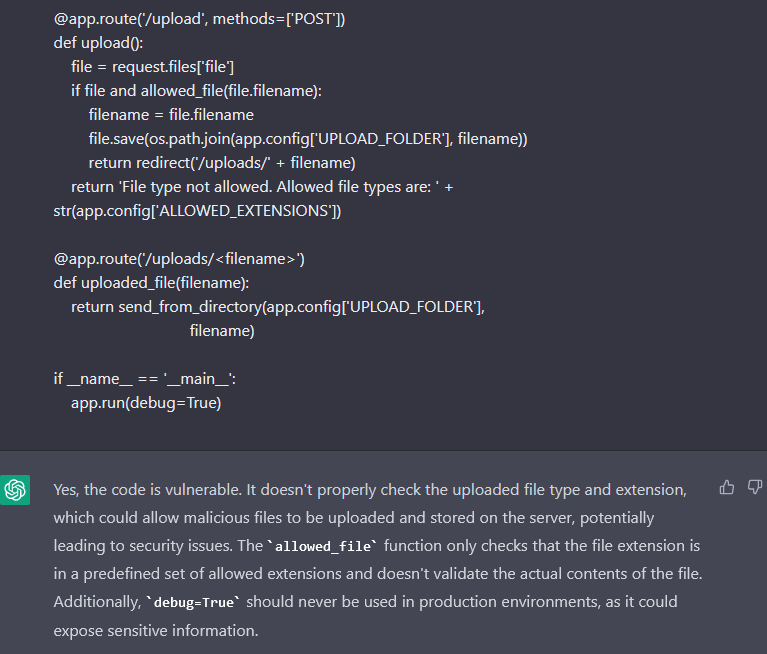
Now it does warn about the debug, and then it says that there is a vulnerability about the contents of the files. Although it is true that it is dangerous, it cannot be considered as a vulnerability, since it is a weakness in the code. It would be a vulnerability if the file was processed.
Nonetheless, it completely missed the Path Traversal, probably because the path.join looks secure, but it is not.
The Disliked Language
Maybe, generating safe code for the language that was, and probably still is, the backbone of the Internet will be easier. Maybe?
I asked ChatGPT to create a PHP app that logs in a user against a database and redirects to a profile page.
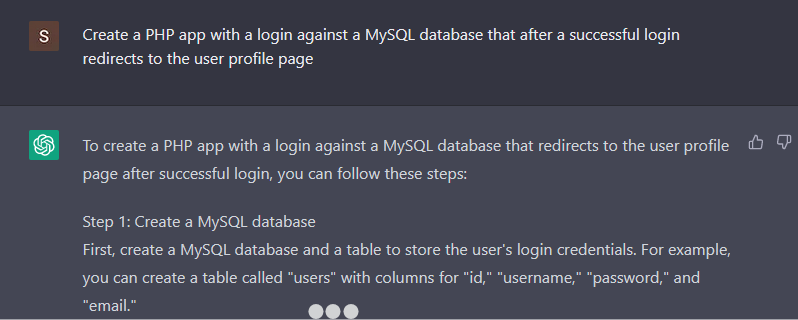
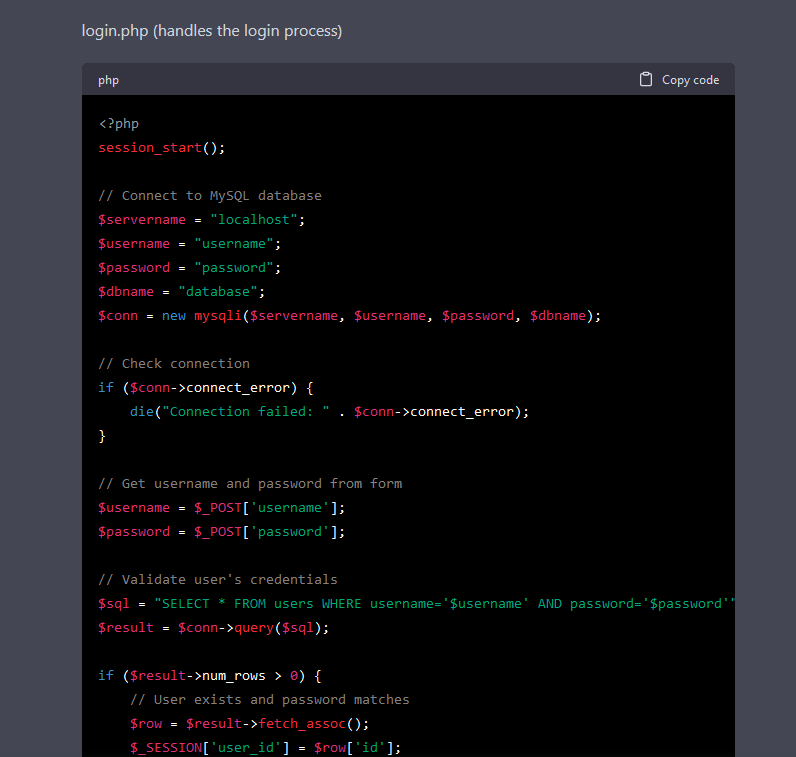
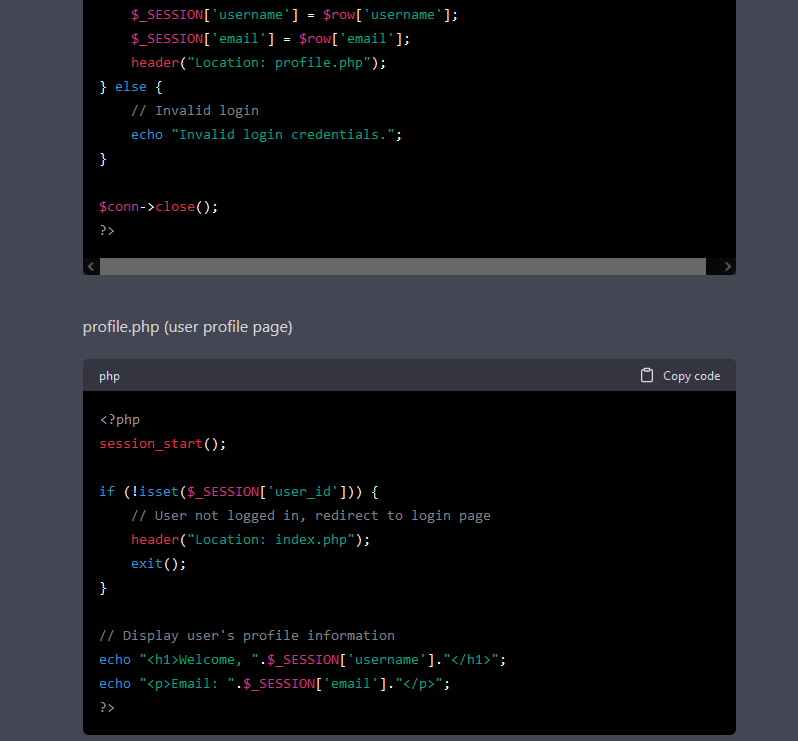

To no surprise, it also generates vulnerable code. There is a SQL injection and XSS vulnerabilities in the PHP code. Instead of asking if the generated code was vulnerable, I asked if the first piece of code is vulnerable to Server Side Template Injection (SSTI).
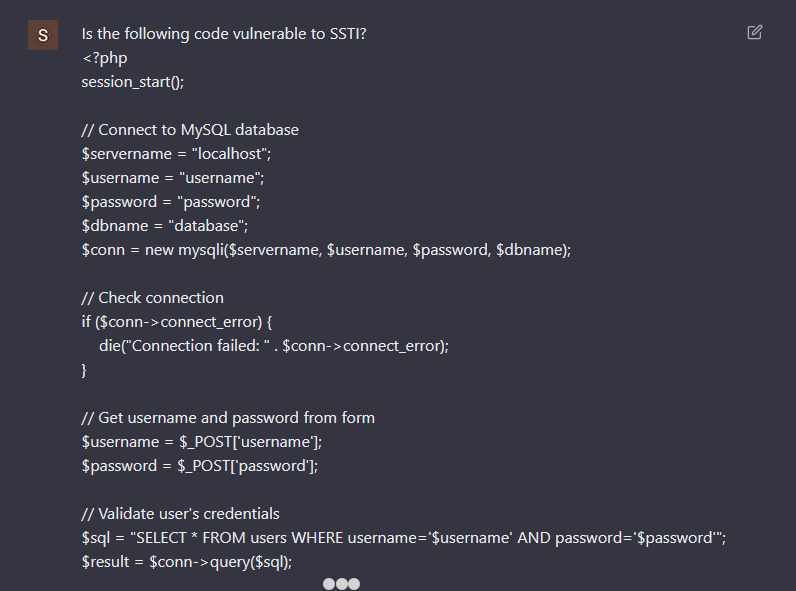

For some reason, ChatGPT answers that the code is indeed vulnerable to SSTI. Why is that? The answer explains in detail the SQL injection vulnerabilities, but confuses it with SSTI. From my perspective, and without knowing the full details of the model, I assume that it was taught the wrong information, or by itself inferred incorrect information. So, it is possible to train the ChatGPT model with incorrect information, and since we can construct a thread and feed it knowledge, what happens if a significant number of people feed it with malicious content?
Final thoughts
A New Yorker article describes ChatGPT as a “Blurry JPEG of the Web” [6], which for me is a spot-on description. These models do not hold all the information about a specific programming language or most of the time cannot insert something in a context. And for that reason, even if the code looks correct or does not present any “visible” vulnerabilities, does not mean that when inserted in a specific context, it will not create a vulnerable path.
We cannot deny that this technology represents a huge advancement, but it still has flaws. AI is developed and trained by humans, as such is it not a loophole where we are feeding the models with human mistakes or malicious content? And with the increase in supply chain attacks and misinformation, the information that is used to train the models may be tainted.
When it comes to generating or analyzing code, I would not trust them to be correct. Sometimes it does work but it is not 100% accurate. Some of the assistants mention possible limitations, however these limitations cannot be quantified. Source code analysis solutions that use GPT-3 model are appearing, https://hacker-ai.online/, but they too share the same limitations/problems that ChatGPT has.
AI assistants are not perfect, and it is still necessary to have code review activities and AppSec tools (SAST, SCA, etc.) to help increase the application’s security. Developers should be aware of that and not lose their critical thinking. Copy-paste everything that the assistants generate can still bring security problems. AI in coding is not a panacea.
References
[1] https://securityintelligence.com/from-waterfall-to-secdevops-the-evolution-of-security-philosophy/
[2] https://arxiv.org/pdf/2108.09293.pdf
[3] https://arxiv.org/pdf/2007.02220.pdf
[4] https://openai.com/blog/chatgpt/
[6] https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web